Improving semantic search performance with feedback loops and hyperparameters
What can we expect from AI when talking about semantic search applied to online commerce? How natural language processing (NLP) applied to product information retrieval in the scope of commerce product search is performing? It depends on the stakeholder. Shoppers expect to find products quickly and easily, while merchants want them well-positioned on the search results page.
The story is that traditional keyword search often falls short of meeting these needs. However, state-of-the-art semantic search has become the ideal complement to keyword search, meeting everyone’s expectations by performing semantic textual similarity (STS) over queries and product fields. This semantic similarity relies on an AI model that produces embeddings via vectors from short text inputs. So, how do we control the model's performance to ensure expectations?
This blog post explores the inner workings of the Empathy Platform semantics ecosystem and reveals what’s behind the good performance of our GenAI search experiences. But first, let’s see how semantic search enhances the product discovery experience for a hybrid search scope.
From keywords to semantics
You already know that traditional search relies on matching keywords in a query with those in a product catalog. This method works well for simple, single-term queries but often fails to capture the context of more complex searches. Semantic search, on the other hand, goes beyond mere keywords by understanding the meaning behind the query and establishing semantic relationships between terms.
For example, consider the query “animal print dress”. A keyword search might return results that include the exact terms animal + print + dress, but a semantic search starts to understand the context and shows animal-printed, zoo-printed, and tiger-printed dresses as results. If you refine the query to “animal print dress for a cocktail party,” the keyword search might struggle to find relevant results due to the lack of exact matches in the catalog. Semantic search, however, understands the context and can suggest dresses suitable for a cocktail party with animal prints, such as tiger or zebra prints.
Evaluating semantic search performance
While implementing semantic search appears straightforward based on the previous examples, many nuances must be considered. For instance, if you search for "colorful dress," a traditional search might yield a few keyword-matching results.
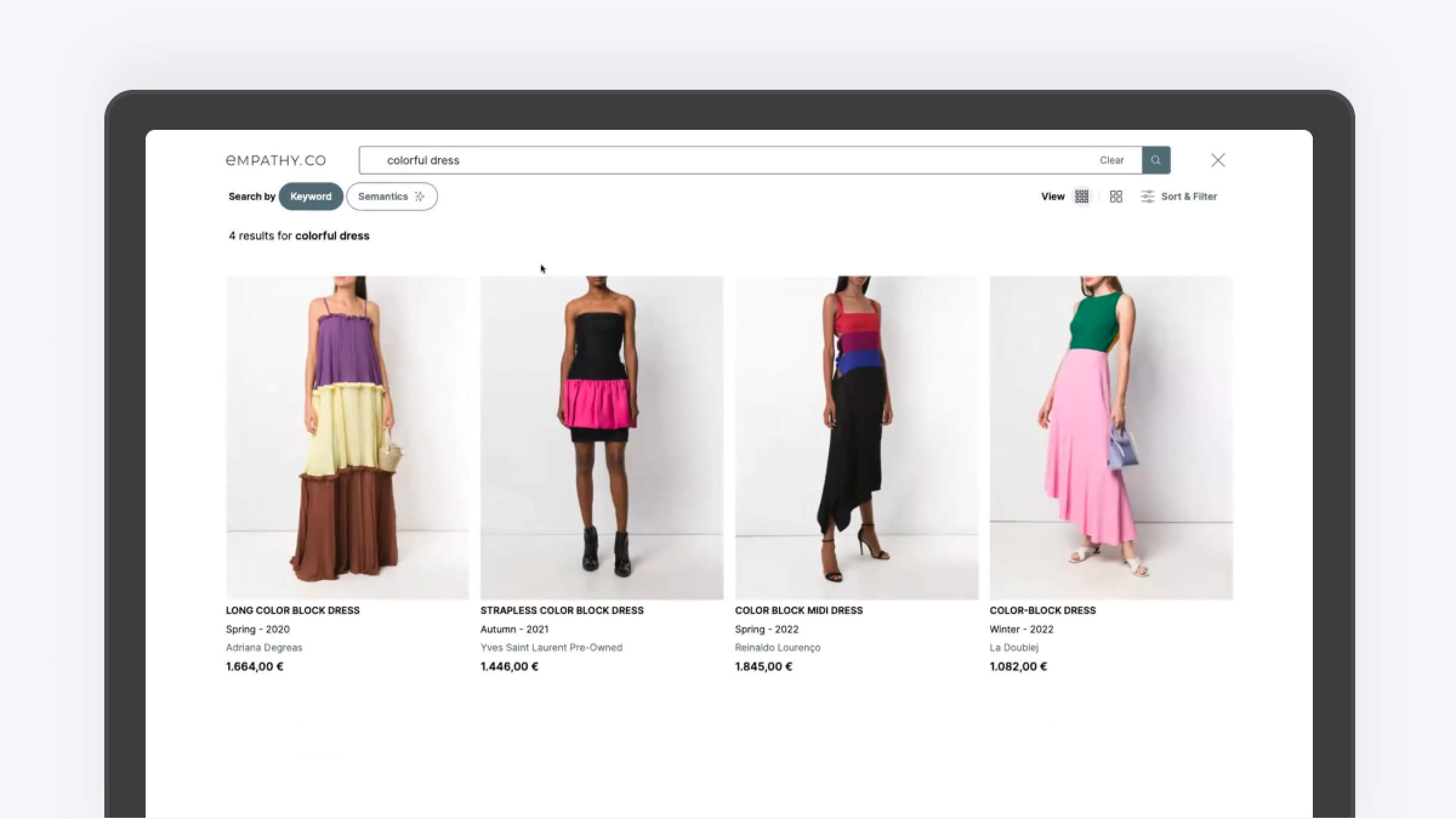
In contrast, semantic search could return a broader range of relevant products. However, there can be discrepancies where semantic search results differ significantly from keyword search, sometimes not making it complementary.
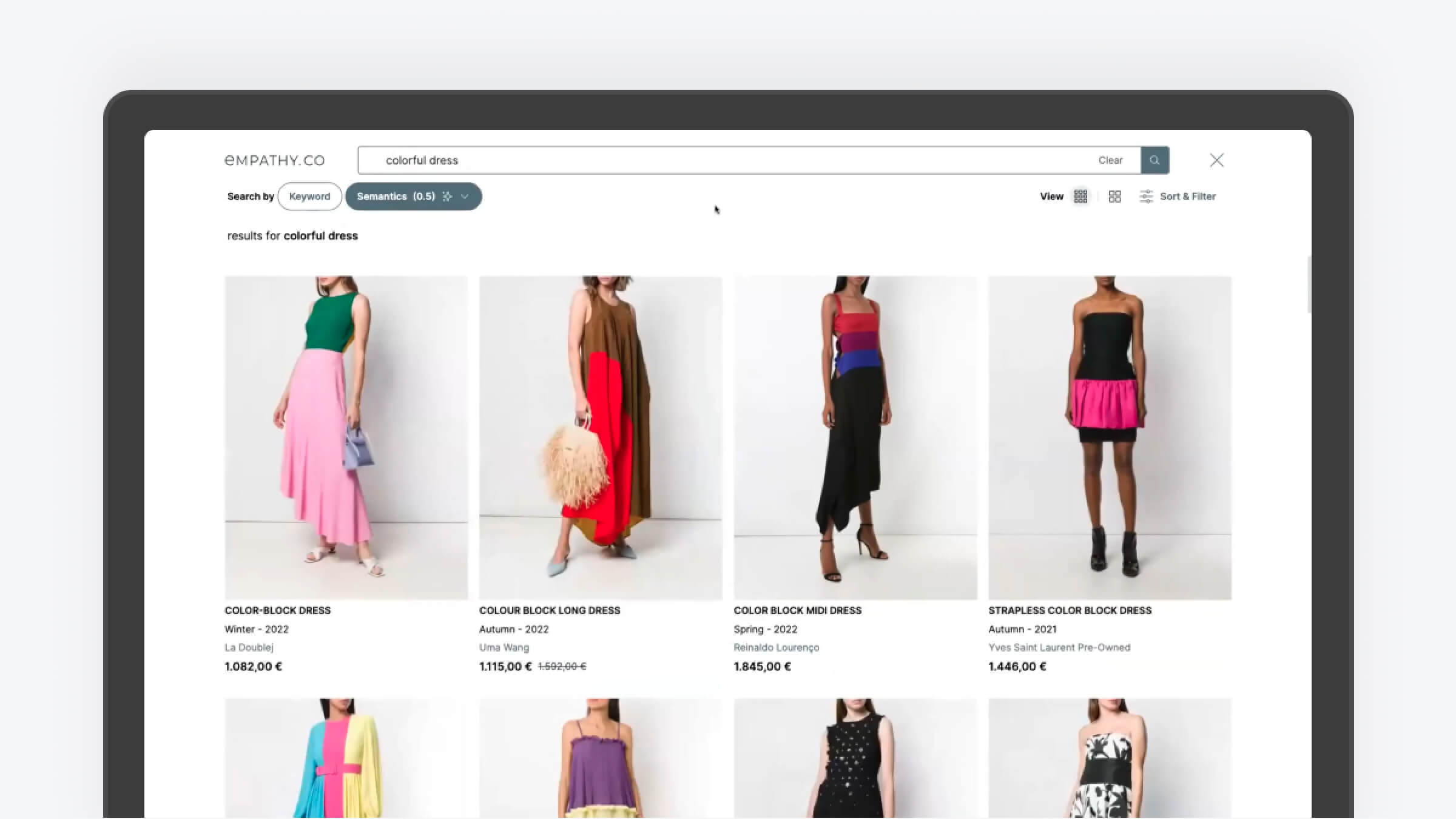
Ensuring the search results enhance the overall user experience requires careful performance monitoring. The key relies on establishing effective operational methods, such as feedback loops' mechanisms, to control the model's performance.
Feedback loops coming into action
Incorporating ML capabilities into a solution requires a mindset shift in the development lifecycle: from functional correctness to data-driven performance evaluation. The MLOps paradigm connects the different stages of a system’s lifecycle in an iterative loop. Thus, one key aspect is enabling feedback recollection and incorporating it into the loop: analysis, training, and validation stages.
Effective operational methods, such as feedback loops, are key to controlling the model's performance. Traditional implicit feedback systems measure clicks, add-to-carts, and other data rates. However, it's crucial to implement explicit human-based feedback to address AI biases and different stakeholder interests.
Empathy.co has developed the Judge the Judgment new tool to help merchants manually tune AI models by evaluating the relevance of search results. This tool allows merchants to categorize results as highly relevant, partially relevant, or irrelevant, fine-tuning the AI model to better meet user expectations.
So, how do feedback systems work in Empathy Platform? The key objective is to show the AI model those queries that are not performing as we expected. So, we perform different steps:
From base models to domain expert models
The process starts with a foundational base model that understands generic language constructs, such as English or Spanish. This model is then refined with business domain-based queries and interactions from the commerce store’s clickstream, creating an expert model tailored to the store’s unique language and context.
Interactive process with feedback loops
After deploying the expert model, we enter a maintenance phase involving continous feedback. Feedback is collected through sentence pairs (query—expected product name) from underperforming queries. This iterative process ensures the model evolves with newly tuned versions to better interpret user intent and product information.
Hyperparams entering the scene
Hyperparameters are crucial in machine learning (ML) as they control the learning process. In other words, a hyperparameter is a higher-level ML parameter whose value is chosen before a learning algorithm is trained—don’t confuse hyperparameters with parameters, as the latter are used to identify variables whose values are learned during training.
Besides feedback loops' mechanisms, we can still contribute to effectively fine-tuning the model directly in the algorithm with hyperparameters. Hyperparameters must be carefully chosen to optimize the model’s performance. For our Sentence-BERT (SBERT) model, trained using Torch, we adjust hyperparameters like learning rate, loss function, and number of epochs.
Optimizing hyperparameters
To optimize the hyperparameters, we define training and evaluation datasets as input. The evaluation dataset, balanced with positive and negative cases, helps assess training effectiveness without affecting the model. Here are some of the most common hyperparameter configurations to start with (note that exact values need to be adjusted depending on the data):
For an unlabeled training dataset (from organic traffic):
loss_function=MultipleNegativesRankingLossbatch_size=256epochs=10learning_rate=0.00002
For a labeled training dataset (from feedback):
loss_function=CosineSimilarityLossbatch_size=64epochs=8learning_rate=0.0001
Evaluating hyperparameters configuration
We monitor the training metrics using the evaluation loss (eval_loss) metric, which measures the average difference between predicted and expected scores. A steadily decreasing eval_loss indicates effective training.
Lessons learned
By integrating feedback loops and optimizing hyperparameters, we've significantly improved the semantic search experience. As Empathy’s founder, Ángel Maldonado, said: “Feedback in semantic search makes explicit the loose ends. It shows the inconclusiveness of many semantic search conclusions while putting Semantics in line with human intellect and brand identity.”
The evolution of semantic search, powered by advanced models and refined through feedback and hyperparameter tuning, offers a promising solution for merchants and shoppers. By continuously iterating and aligning AI performance with human expectations, we can create search experiences that are accurate, contextually relevant, and trusted.
The continuous refinement of our AI models ensures that Empathy Platform remains at the forefront of innovative search technology. This iterative approach, combined with other search fine-tuning and configuration tools such as product boosting and promotions, meets diverse stakeholder needs and sets new standards for excellence in Empathy Platform semantic search.
Empathy continues to innovate through Empathy.AI, the space where we research, design, and develop AI search systems built on self-hosted, private, and sustainable infrastructure.
The features, tools, and capabilities within Empathy Platform are shaped through this ongoing work, grounded in real-world needs and driven by continuous research, experimentation, and iteration.
Keep an eye on Empathy.AI (opens new window) and explore the latest articles in our blog to stay up to date.