Fine-tuning Mistral for an enhanced content search experience (part II)
A backend perspective
This is the second post in a four-part series focusing specifically on the backend perspective. The first post provided an overview, and subsequent posts will dive deep into the infrastructure and UX perspectives.
As we said in the previous post, we’re always striving to push the boundaries of innovation, especially in search experiences. For this series, we’ll focus specifically on how we improved our developer portal search capabilities.
This post details our backend journey, highlighting the technical processes and challenges overcome in fine-tuning Mistral for our platform. Let’s then share some insights!
The backend journey
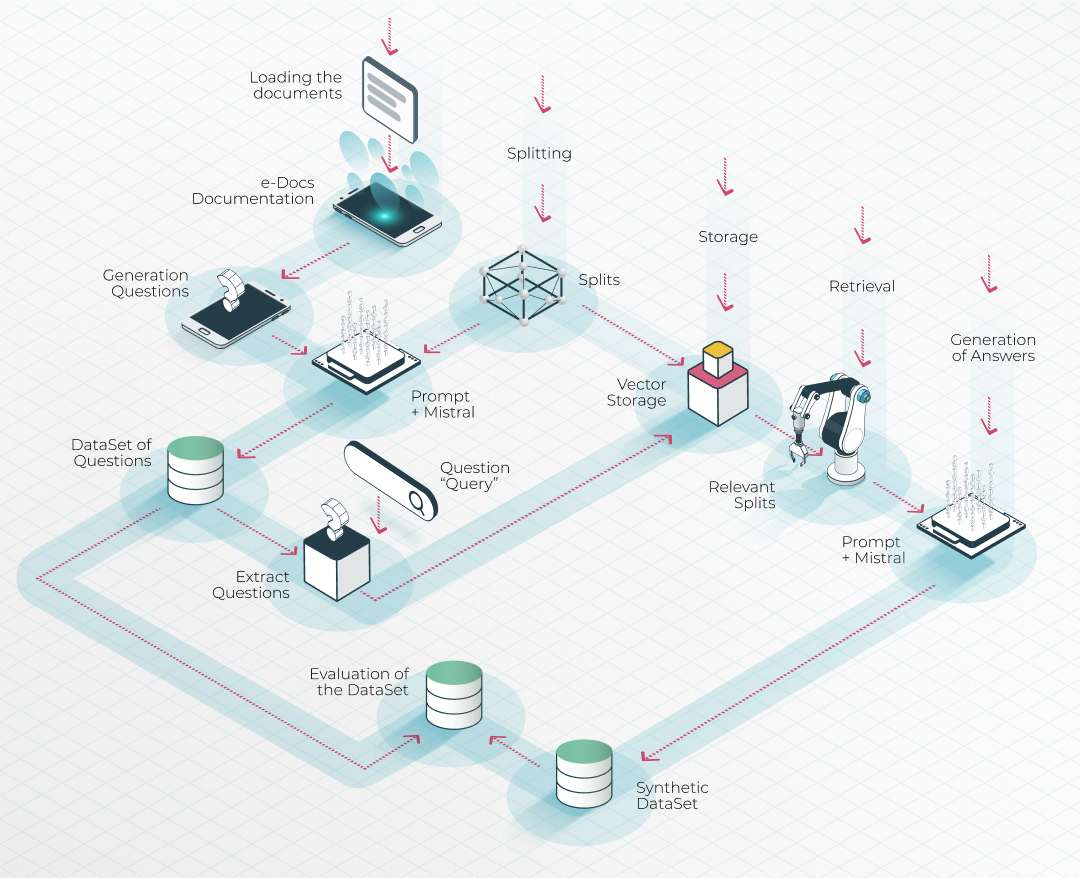
The backend team embarked on this project with the intention of creating a comprehensive and neutral dataset for the Mistral model. To achieve this, three microteams were formed, each tasked with generating diverse data sources.

Backend development process: 1. Datasets generation using diverse indexing methods. 2. Unify the datasets in one. 3. Fine-tune the Mistral model with the combined dataset based on the Empathy Platform official documentation. 4. Deploy the model in the EPDocs portal.
Diverse data sources
- Team one & team two used an in-house Retrieval Augmented Generation (RAG) system to generate datasets locally based on the Empathy Platform documentation.
- Team three used a Python library with Mistral to generate datasets of questions.
This multi-source approach ensured a well-rounded dataset for the model.
Data processing with RAG: indexing and question generation
For the RAG dataset generation approach, the documentation in the Empathy Platform portal was split into embeddings that were stored in a vector database. This was followed by generating questions synthetically, allowing the system to infer and generate accurate answers in combination with the Mistral model.
Unifying the datasets
Once the datasets from the three teams were prepared, they were standardized into a common format, creating a robust combined dataset. This step was crucial for effectively fine-tuning the Mistral model.
Fine-tuning and deployment
With the unified dataset ready, the next step was fine-tuning the Mistral model. This involved a custom script and workflow to tailor the model for our Empathy Platform documentation. The fine-tuned model was then deployed on the EPDocs documentation portal, ready for people's interactions.
Final thoughts on backend innovations
The backend work on fine-tuning Mistral was essential in enhancing the search functionality of our developer portal. By leveraging diverse data sources, advanced AI models, and a unified dataset approach, the backend teams finally manage to create a content search experience that is both powerful and secure.
Try it out!
Love AI. Love privacy. Type away! on our search bar above and try out our new HolonSearch Privacy-First Generative Content Search right now!
Keep reading!
This backend perspective is part of our broader effort to innovate and improve user search interactions. Read more about our journey from the infrastructure and UX perspectives.